Overview
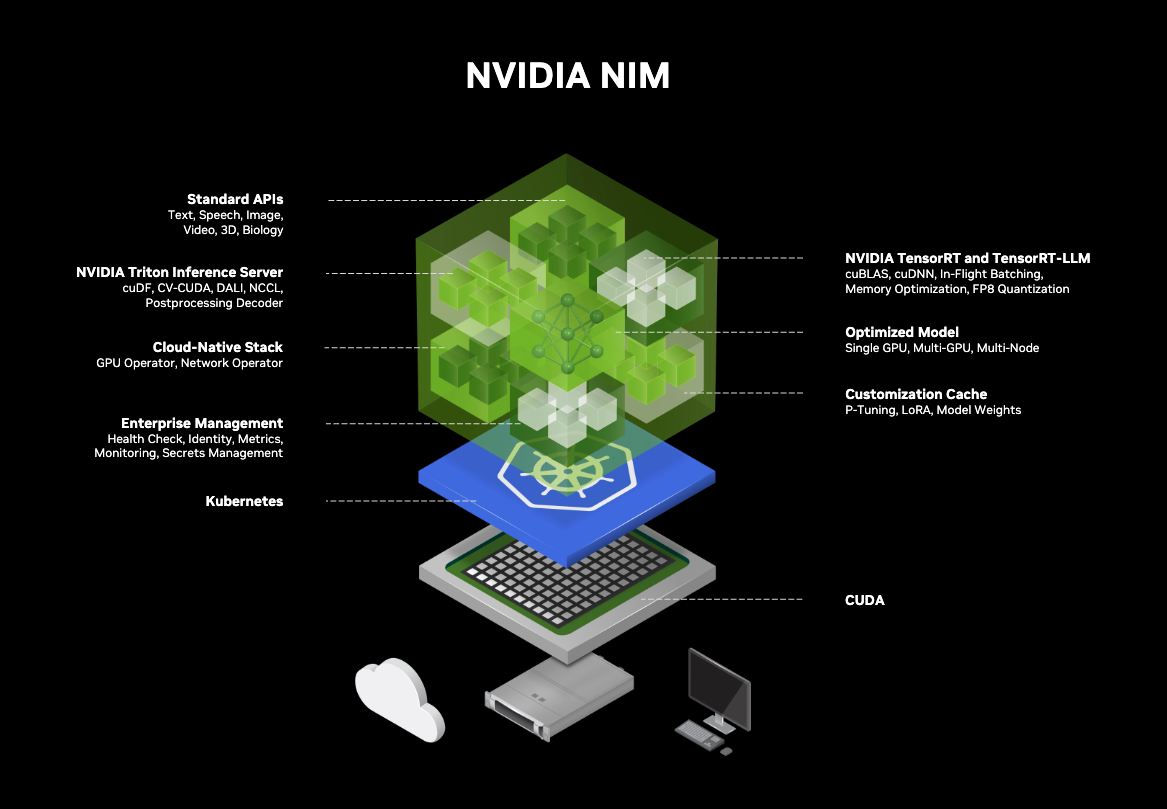
NVIDIA NIM™
NVIDIA NIM™ are performance-optimized, portable inference microservices designed to accelerate and simplify the deployment of AI models. NIM are containerized, so you can self-host GPU-accelerated pretrained, fine-tuned, and customized models in the cloud, data center, or on your own workstation.
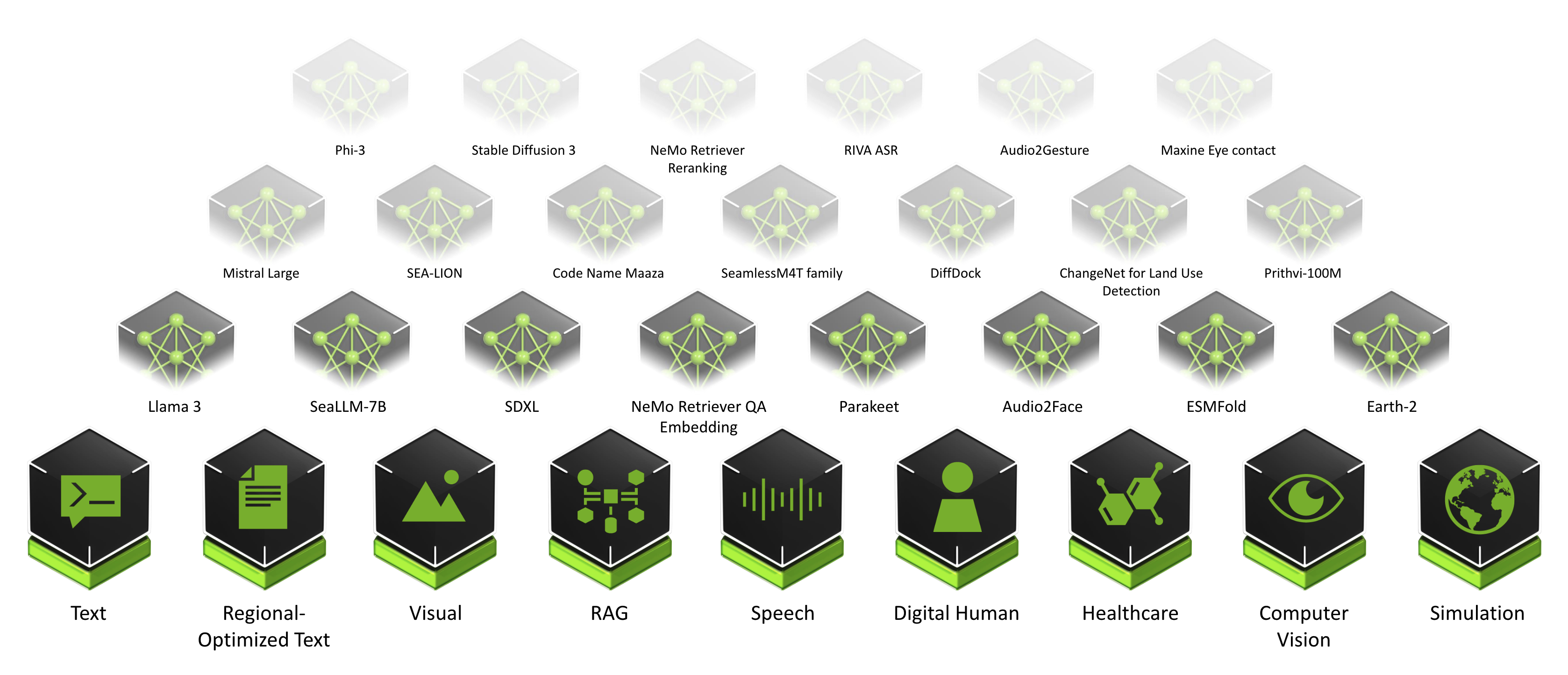
The ever-growing catalog of NIM microservices contains models for a wide range of AI use cases, from chatbot assistants to computer vision models for video processing. The image below shows some of the NIM microservices, organised by use case.
For Developers
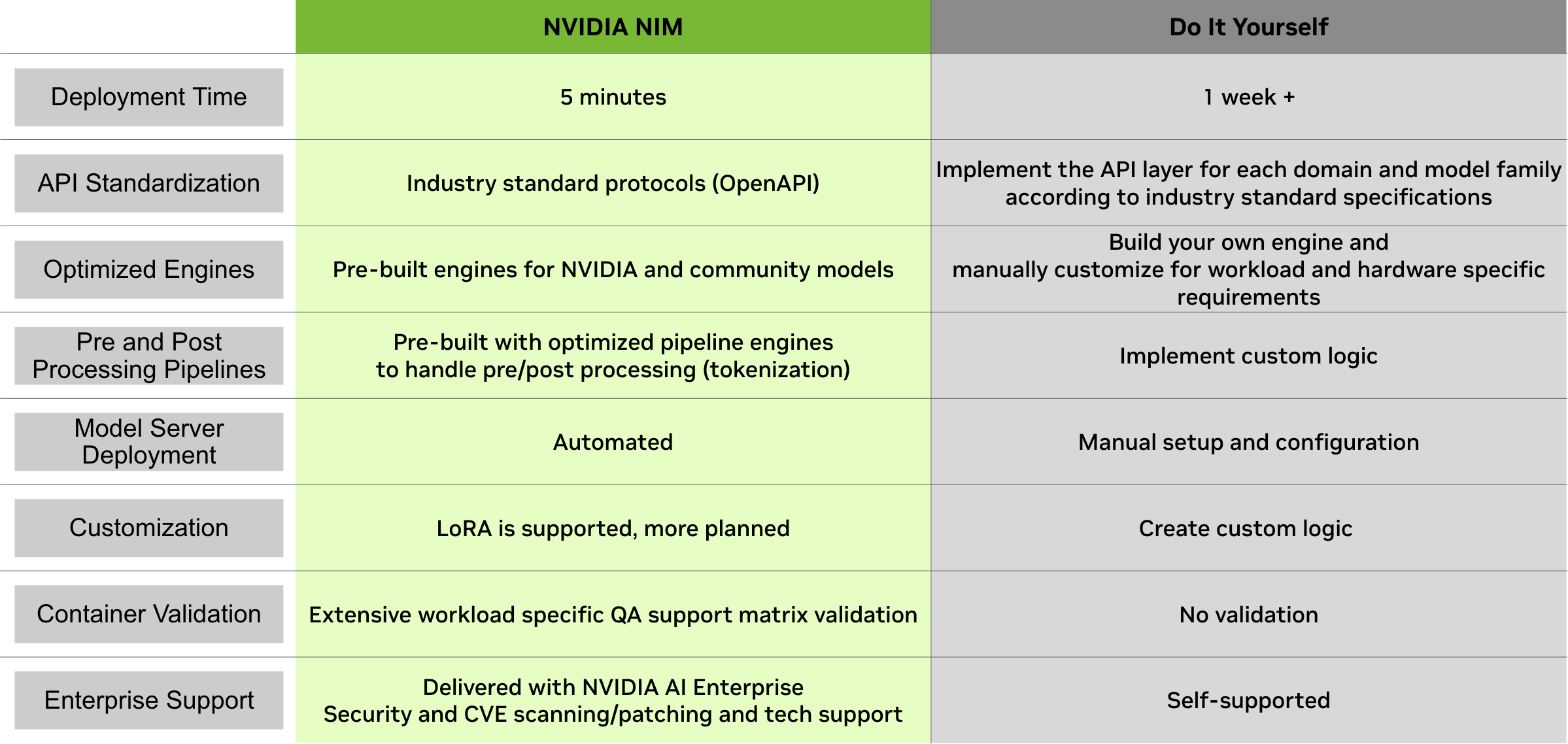
NIM provides a simplified way to integrate AI models into your applications by exposing industry standard APIs and abstracting away model inference internals such as execution engine and runtime operations. NIM are the most performant option available, whether with TRT-LLM, vLLM, or others. With NIM you can use AI models by simply calling their hosted endpoints.
For IT Professionals and DevOps
On the infrastructure side, NIM make it easy to deploy, manage and optimize AI infrastructure, reducing engineering resources required to set up and maintain accelerated models.
Use Cases
NIM microservices expose industry-standard API endpoints that allow you to quickly test and develop. Models are categorized by use cases and come with full API reference documentation, whether you want to work with a specific model or explore all available models for your use case.
Large Language Models
Handle a wide range of text generation tasks, such as question answering, summarization, reasoning, and code generation.
Retrieval Models
Optimize text question-answering retrieval and improve accuracy by reranking potential candidates.
Visual Models
Deliver advanced image and video synthesis capabilities, utilizing techniques like Adversarial Diffusion Distillation and latent diffusion models.
Multimodal Models
Combine visual and textual understanding for enhanced performance across tasks such as image understanding, text generation, and code generation, leveraging multiple modalities of data (text + images).
Healthcare Models
AI model APIs for generative and predictive drug discovery, medical imaging, and genomics analysis.
Route Optimization Models
Optimize logistics routing, supporting various vehicle routing problem variants and enabling dynamic, data-driven decision-making.
Climate Simulation Models
Leverage FourCastNet for accurate, high-resolution, and fast-timescale weather forecasting, advancing climate simulation and weather prediction through AI.
Updated over 1 year ago