Retriever NIMs
NVIDIA NeMo Retriever text embedding NIM APIs provide easy access to state-of-the-art models that are foundational building blocks for enterprise semantic search applications, delivering accurate answers quickly at scale. Developers can use these APIs to create robust copilots, chatbots, and AI assistants from start to finish. NeMo Retriever text embedding models are built on the NVIDIA software platform, incorporating NVIDIAⓇ CUDAⓇ, TensorRTTM, and TritonTM Inference Server to offer out-of-the-box GPU acceleration.
NeMo Retriever text embedding NIM
Boost text question-answering retrieval performance, providing high quality embeddings for many downstream NLP tasks.
NeMo Retriever text reranking NIM
Enhance the retrieval performance further with a fine-tuned reranker, finding the most relevant passages to provide as context when querying an LLM. See the NVIDIA NIM for text reranking documentation for more information.
Available Models
You can access the available models here
Select models are available as downloadable container images and supported with an NVIDIA AI Enterprise entitlement. These select models have additional OpenAI API spec details for running self-hosted localized NIMs. Please refer to the Downloadable NIMs section for more details.
This diagram shows how NeMo Retriever APIs can help a question-answering RAG application find the most relevant data in an enterprise setting.
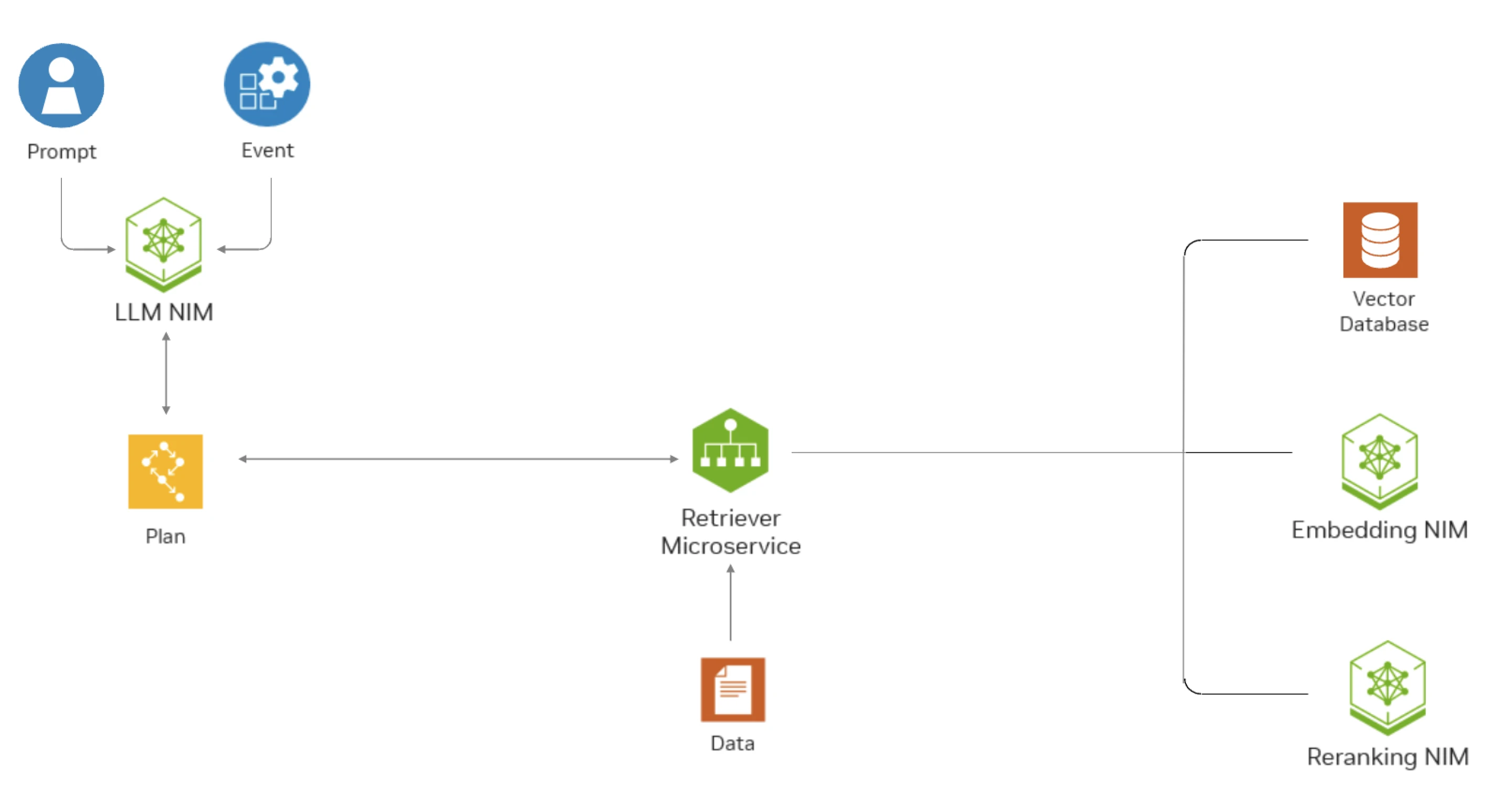
Architecture
Each NeMo Retriever NIM packages a model, such as NV-EmbedQA-Mistral7B-v2, into a Docker container image. All NeMo Retriever NIM Docker containers are accelerated with NVIDIA TritonTM Inference Server and expose an API compatible with the OpenAI API standard.
For a full list of supported models, see Supported Models.
Updated almost 2 years ago