Downloadable NIM QSG
Within this Quick Start Guide, you will learn how you can self-host an LLM model by deploying NIM to a your own infrastructure using a trial license of NVIDIA AI Enterprise or an NVIDIA Developer Account.
📒 NOTE: For this guide, we will reference the llama-3-8B-instruct model. Update the model name to suit your requirements. For example, for a llama3-70b-instruct model.
-
Access the NVIDIA API Catalog within your web browser.
-
Within the search bar, type llama3 and select the llama3-8B-instruct model:
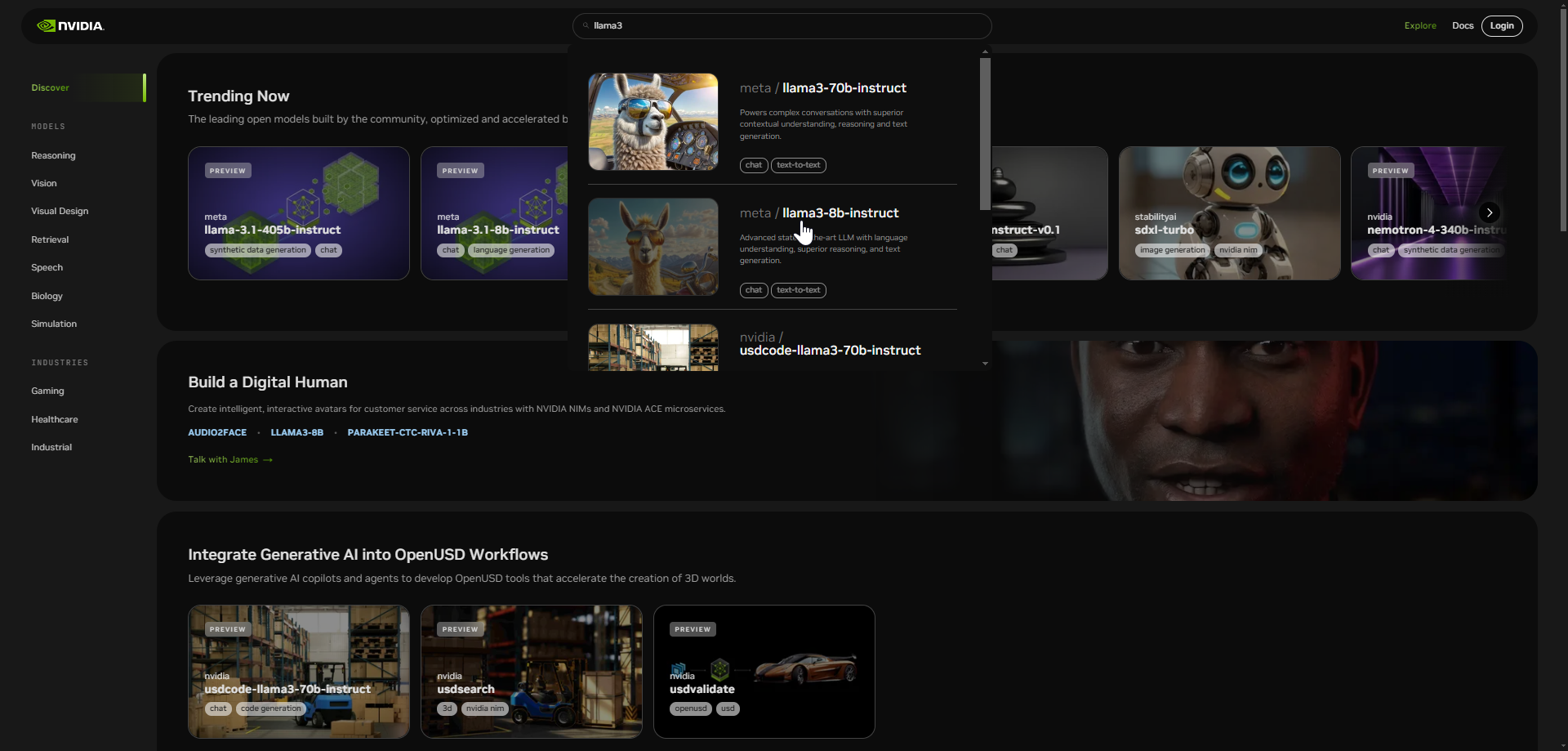
This will bring you to the model page. On the left pane is the preview tab, here you can ask NIM LLM a question using the API endpoint.
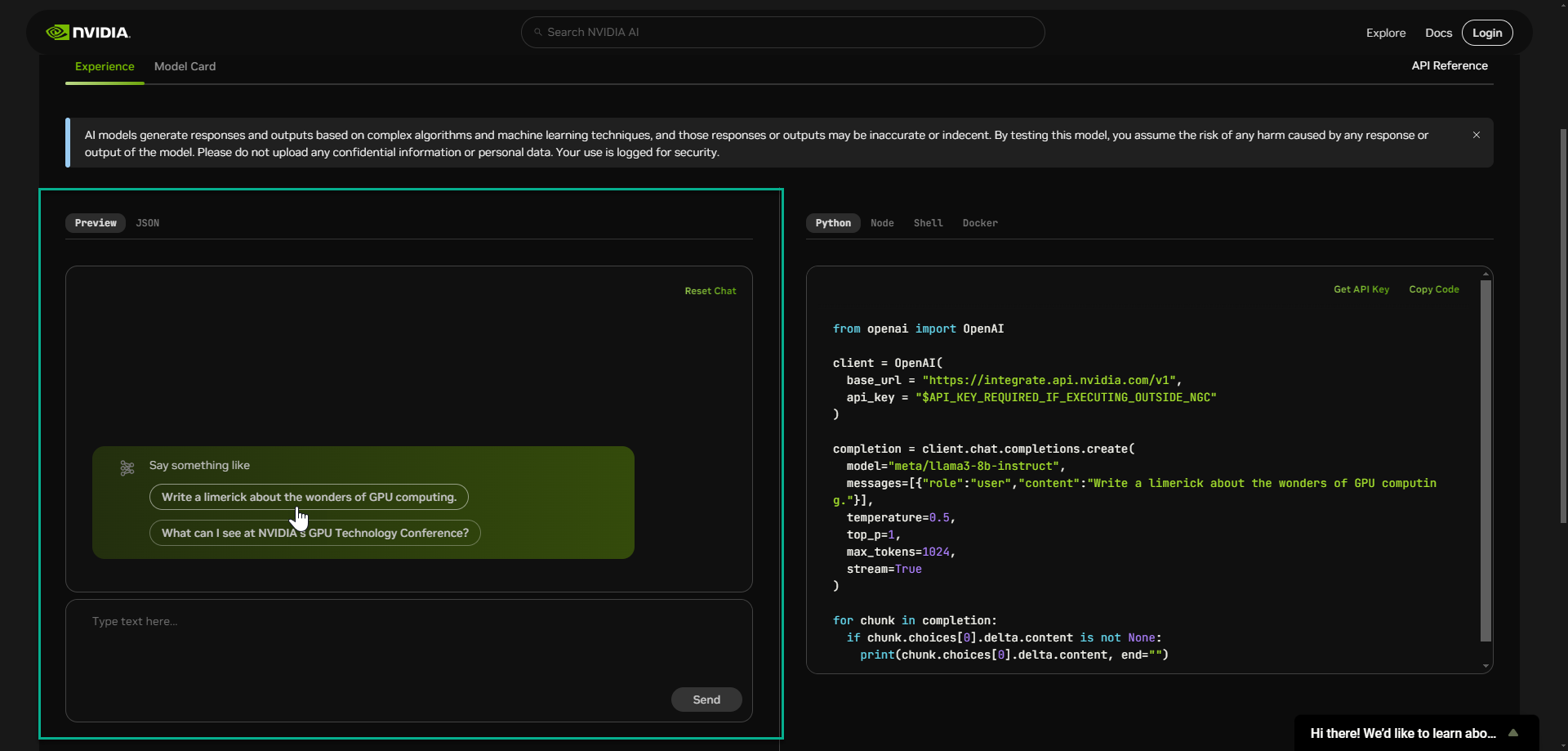
The sample question provided is “Write a limerick about the wonders of GPU computing.” This technology is using a hosted API endpoint on NVIDIA DGX Cloud.
You can also download the NIM so that you can deploy the NIM on the infrastructure of your choice. This provides you with the ability to customize the model and gain full control of your IP and AI application.
-
To download the NIM for use within your own environment, select “Build with this NIM” in the right-hand corner.
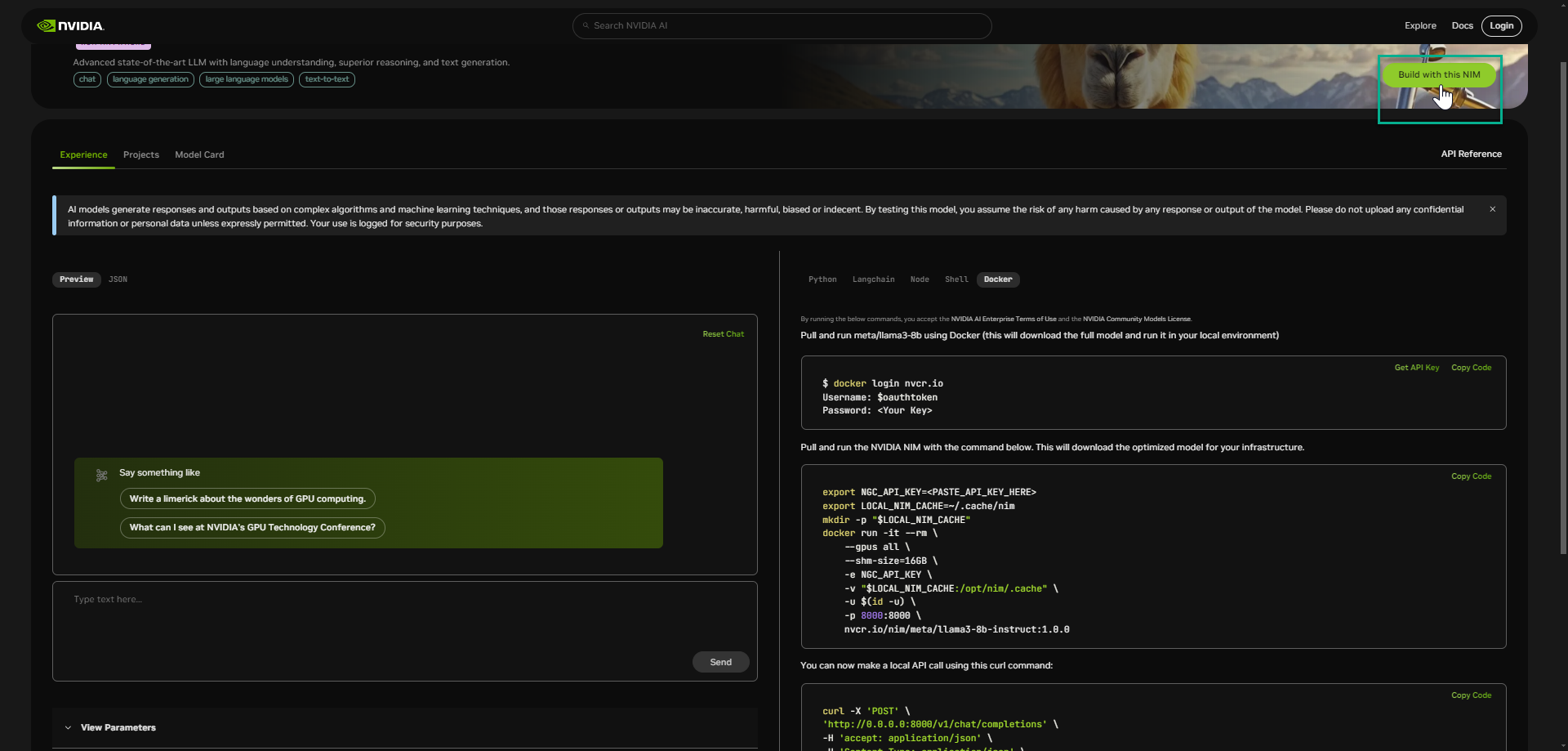
This will bring you to a sign-up page to gain access to NVIDIA NIM.
-
Enter your corporate email, this will sign you up for a trail license of AI Enterprise.
If you do not have a corporate email, you can use a personal email which will sign you up for Developer Account.
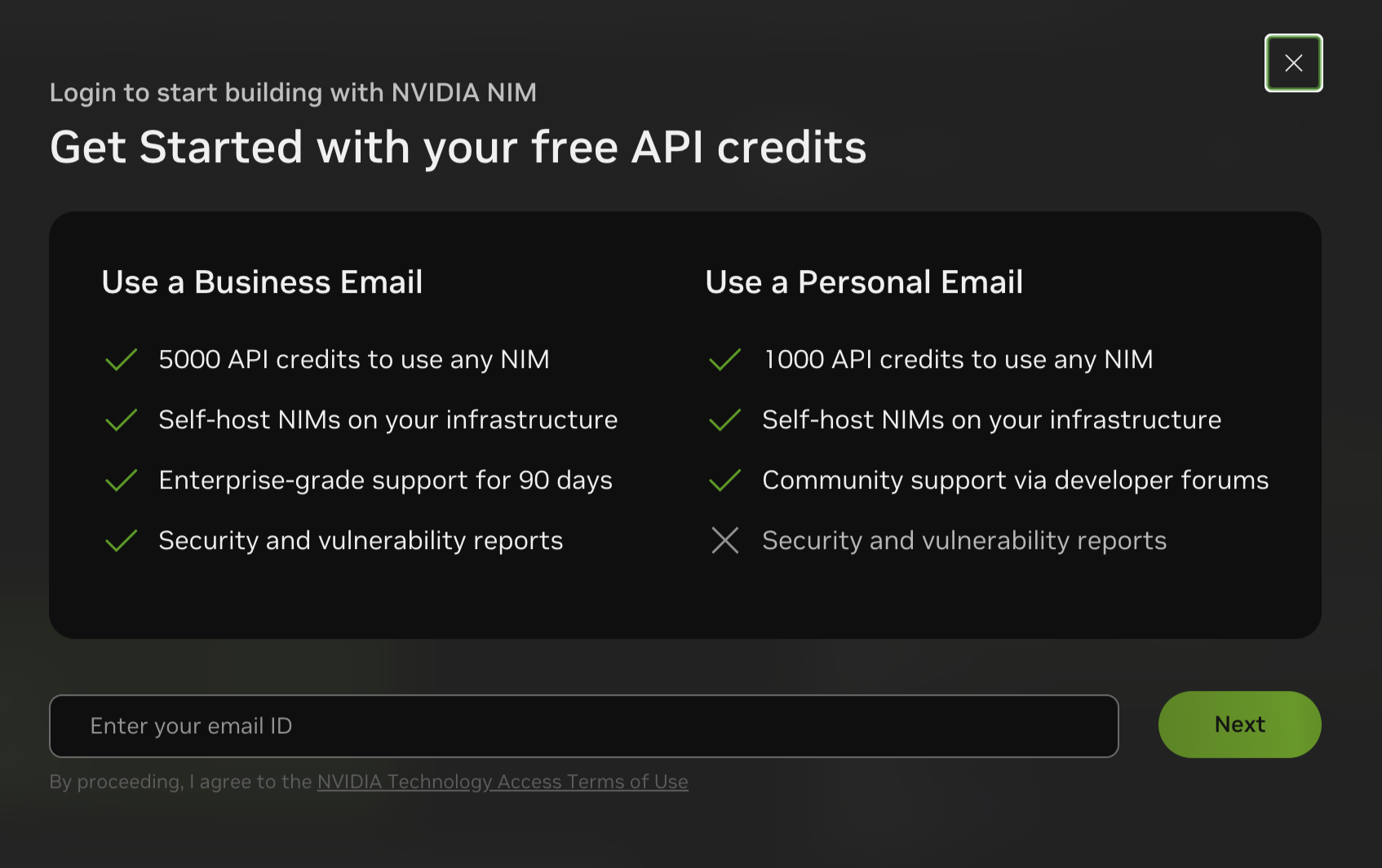
-
For existing account holders, enter in you account credentials. New accounts, will be prompted to create an account.
-
A verification email will be sent to the email ID, please check you email inbox and select Verify Email Address from the NVIDIA Accounts team.
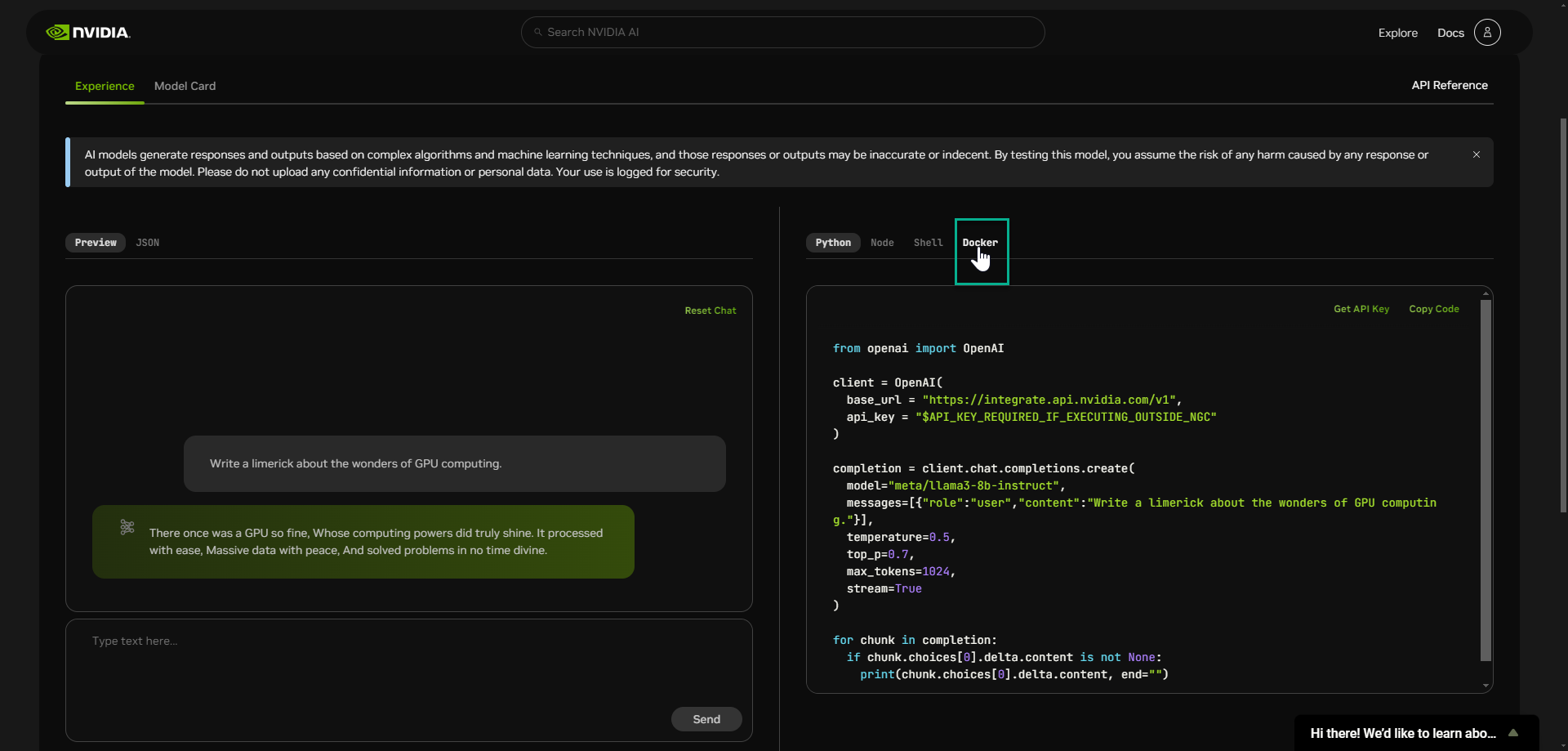
You are able to interact with NIMs using your choice of Python, Node, Shell, or Docker through the Open AI Chat Completions Endpoint.
📒 NOTE: We will use Docker in the following example, but you should choose the method of your choice. This will be used in the next step when you download the NIM.
This key authenticates you to download and run a NIM on your local infrastructure with NVIDIA AI Enterprise.
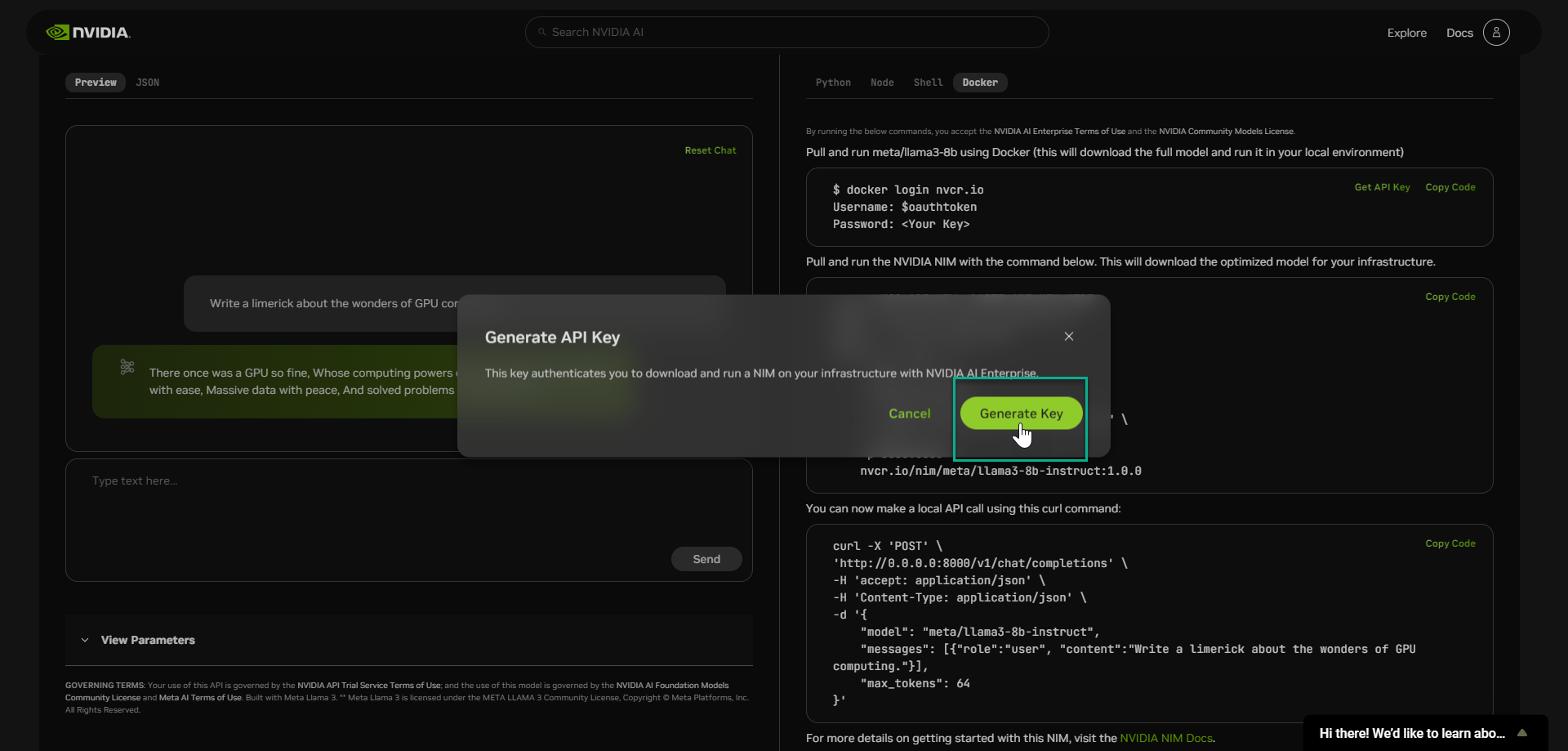
Do not share it or store it in a place where others can see or copy it.
📒 NOTE: A key was automatically generated for you, this was granted to you via an auto generated NGC Org.
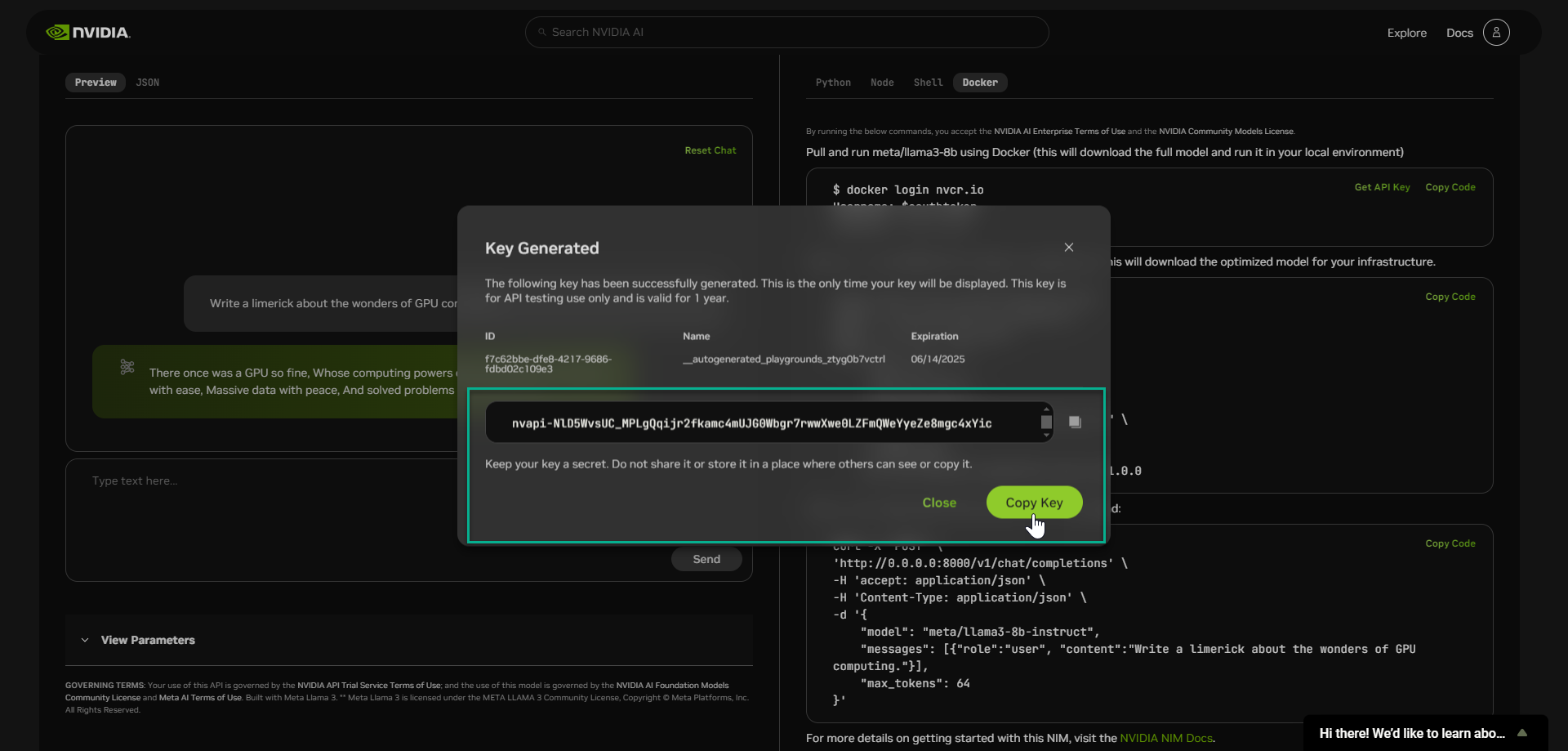
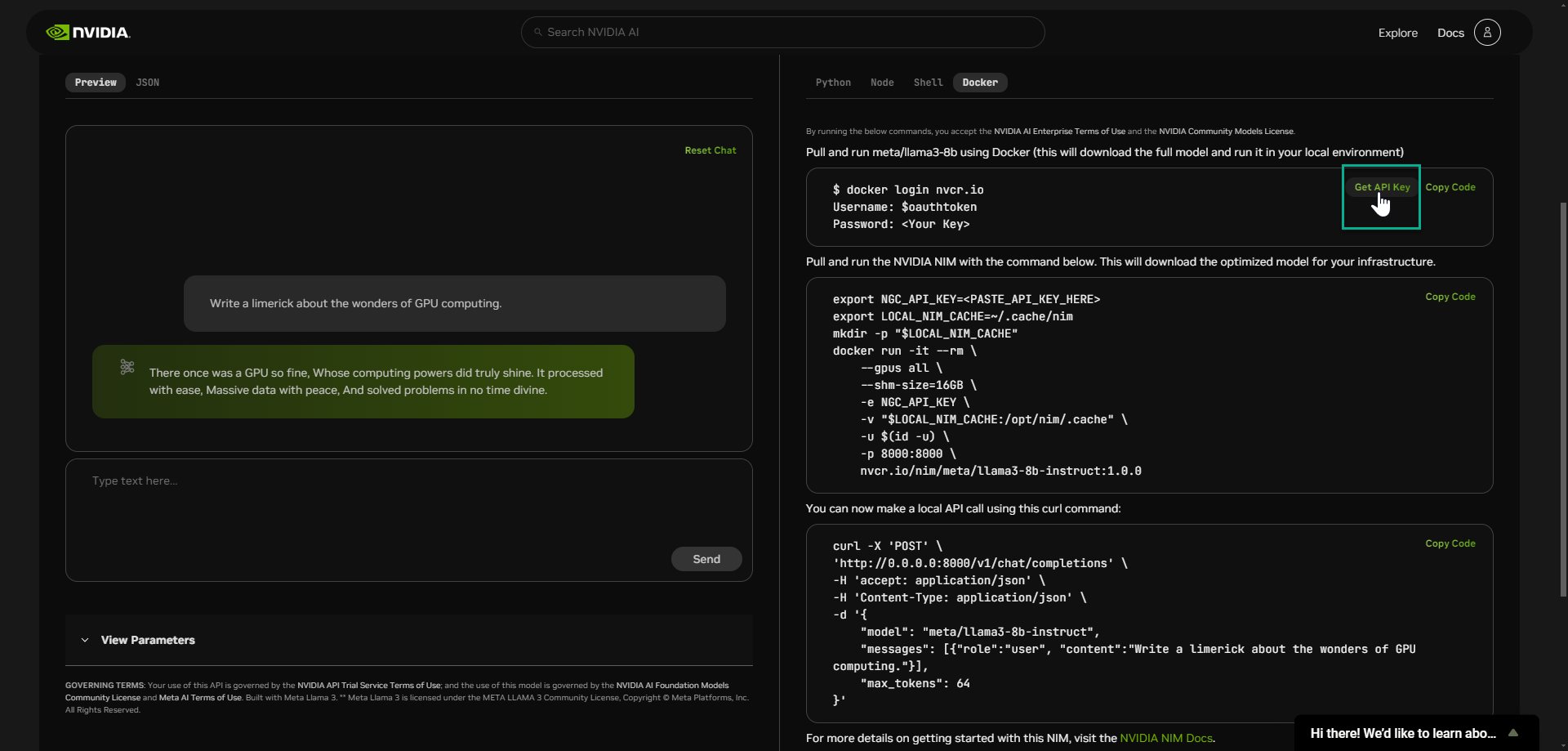
This API key allows you to pull and run meta/llama3-8B NIM using Docker within your local environment.
❗️IMPORTANT: Ensure you have met LLM NIM prerequisites before proceeding further.
Next, you will pull and deploy the LLM NIM using using Docker and the code snippets provided.
-
As illustrated below, use click Copy Code and paste the commands into a new terminal which connects you to your local environment.
📒 NOTE: Paste your API key into section.
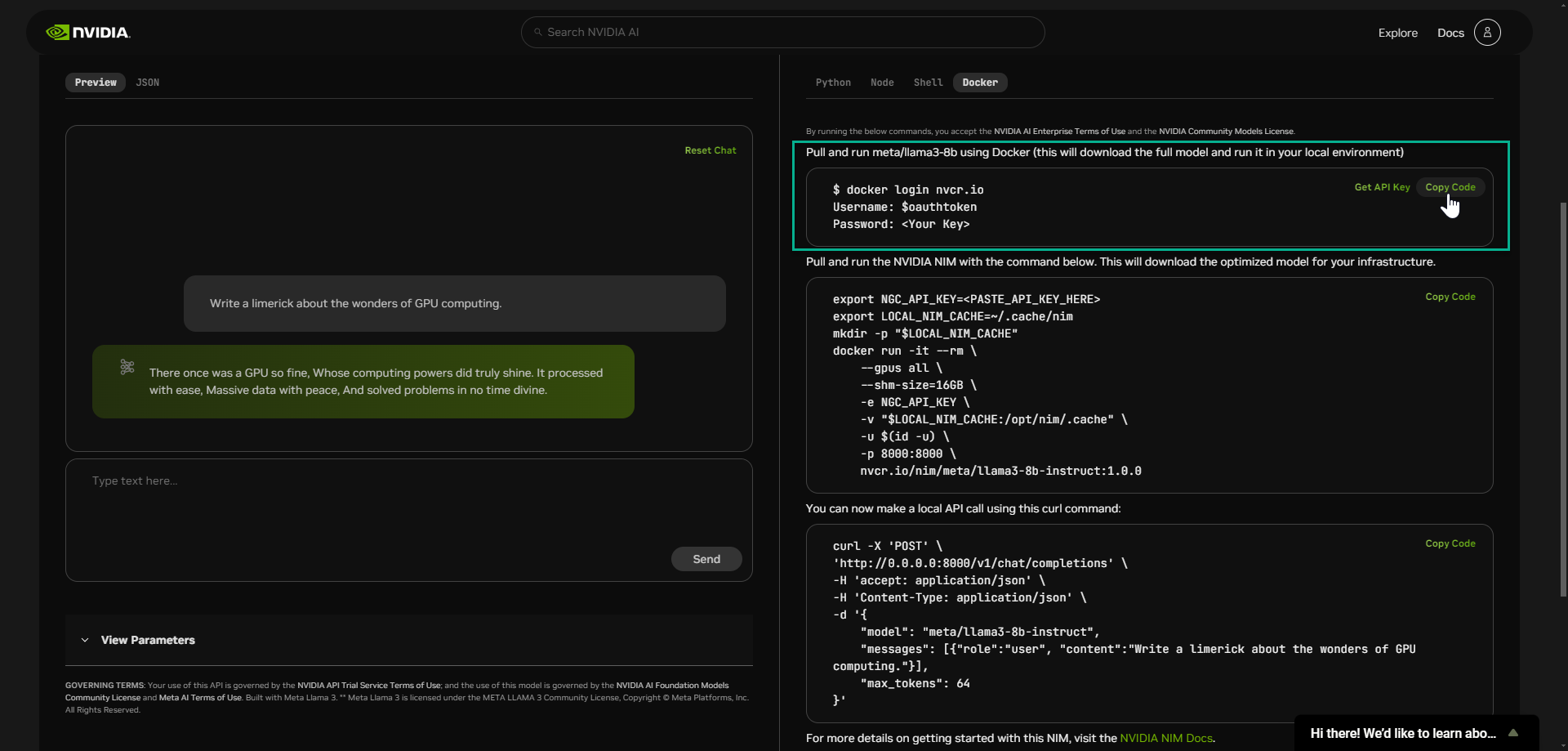
The optimized model is being downloaded onto your local infrastructure. During startup, the NIM container downloads the required resources and begins serving the model behind an API endpoint. The following message indicates a successful startup.
INFO: Application startup complete
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
Once you see this message you can validate the deployment of NIM by executing an inference request.
-
Click Copy Code and paste commands in your local environment terminal to make a local API call using the provided curl command.
Want to learn more?
Learn more about configuring self-hosted NIM's using NVIDIA AI Enterprise here
Updated over 1 year ago