Llama-Guard-4-12B Overview
Description:
Llama-Guard-4-12B is a 12-billion parameter, dense, multimodal safety classifier developed by Meta. It is designed to evaluate both text and image inputs for safety, classifying content in large language model (LLM) prompts and responses. The model outputs text indicating whether the content is safe or unsafe, and if unsafe, it lists the violated content categories.
This model is ready for commercial/non-commercial use.
Third-Party Community Consideration
This model is not owned or developed by NVIDIA. It has been developed and built to Meta's requirements for safety classification in multimodal LLM applications.
See the Llama-Guard-4-12B Model Card for more details.
License and Terms of Use:
GOVERNING TERMS: The trial service is governed by the NVIDIA API Trial Terms of Service; and the use of this model is governed by the NVIDIA Community Model License. ADDITIONAL INFORMATION: Llama 4 Community Model License. Built with Llama.
Deployment Geography:
Global
Use Case:
Intended for developers and organizations seeking to implement safety classification in LLM applications, including filtering of unsafe content in both inputs and outputs across text and image modalities.
Hazard Taxonomy and Policy
The model is trained to predict safety labels on the categories shown below, based on the MLCommons safety taxonomy. We include an additional category, Code Interpreter Abuse, for text-only tool-call use cases.
| Hazard categories | |
|---|---|
| S1: Violent Crimes | S2: Non-Violent Crimes |
| S3: Sex-Related Crimes | S4: Child Sexual Exploitation |
| S5: Defamation | S6: Specialized Advice |
| S7: Privacy | S8: Intellectual Property |
| S9: Indiscriminate Weapons | S10: Hate |
| S11: Suicide & Self-Harm | S12: Sexual Content |
| S13: Elections | S14: Code Interpreter Abuse (text only) |
S1 - Violent Crimes
Responses that enable, encourage, or endorse the commission of violent crimes, including: (1) unlawful violence toward people (ex: terrorism, genocide, murder, hate-motivated violent crimes, child abuse, assault, battery, kidnapping) and (2) unlawful violence toward animals (ex: animal abuse)
S2 - Non-Violent Crimes
Responses that enable, encourage, or endorse the commission of non-violent crimes, including: (1) personal crimes (ex: labor trafficking, threats, intimidation, hate-motivated non-violent crimes), (2) financial crimes (ex: fraud, scams, money laundering), (3) property crimes (ex: theft, arson, vandalism), (4) drug crimes (ex: creating or using regulated substances), (5) weapons crimes (ex: producing unlicensed firearms), and (6) cyber crimes (ex: hacking)
S3 - Sex-Related Crimes
Responses that enable, encourage, or endorse the commission of sex-related crimes, including: (1) sex trafficking, (2) sexual assault (ex: rape), (3) sexual harassment (physical, verbal, or visual), and (4) prostitution
S4 - Child Sexual Exploitation
Responses that contain, describe, enable, encourage, or endorse the sexual abuse of children
S5 - Defamation
Responses that are both verifiably false and likely to injure a living person’s reputation
S6 - Specialized Advice
Responses that contain specialized financial, medical, or legal advice, or that indicate dangerous activities or objects are safe
S7 - Privacy
Responses that contain sensitive, nonpublic personal information that could undermine someone’s physical, digital, or financial security
S8 - Intellectual Property
Responses that may violate the intellectual property rights of any third party
S9 - Indiscriminate Weapons
Responses that enable, encourage, or endorse the creation of indiscriminate weapons, including: (1) chemical weapons (ex: nerve gas), (2) biological weapons (ex: anthrax), (3) radiological weapons (ex: cobalt bombs), (4) nuclear weapons (ex: fission bombs), and (5) high-yield explosive weapons (ex: cluster munitions)
S10 - Hate
Responses that demean or dehumanize people on the basis of their sensitive, personal characteristics (i.e., race, color, ethnicity, national origin, disability, religious affiliation, caste, sexual orientation, sex, gender identity, and/or serious disease)
S11 - Suicide & Self-Harm
Responses that enable, encourage, or endorse acts of intentional self-harm, including: (1) suicide, (2) self-injury (ex: cutting), and (3) disordered eating
S12 - Sexual Content
Responses that contain erotica
S13 - Elections
Responses that contain factually incorrect information about electoral systems and processes, including in the time, place, or manner of voting in civic elections
S14 - Code Interpreter Abuse (text-only)
Responses that seek to abuse code interpreters, including those that enable denial of service attacks, container escapes or privilege escalation exploits
Release Date:
- Build.Nvidia.com: May, 2025
- Hugging Face: April 29, 2025
Reference(s):
Model Architecture:
- Architecture Type: Transformer-based
- Network Architecture: Dense feedforward early-fusion architecture, pruned from Llama 4 Scout by removing routed experts and router layers, retaining only the shared expert.
- This model was developed based on: Llama 4 Scout
- This model has: 12 billion model parameters
Input:
- Input Type(s): Text, Image
- Input Format(s): String (text), Image files
- Input Parameters: 2D
- Other Properties Related to Input: Supports multiple images in prompts; multilingual text support
Output:
- Output Type(s): Text
- Output Format: String
- Output Parameters: 1D
- Other Properties Related to Output: Generates text indicating safety classification and lists violated content categories if applicable
Our Al models are designed and/or optimized to run on NVIDIA GPU-accelerated systems. By leveraging NVIDIA's hardware (e.g. GPU cores) and software frameworks (e.g., CUDA libraries), the model achieves faster training and inference times compared to CPU-only solutions.
Supported Hardware Microarchitecture Compatibility:
- NVIDIA Ampere
- NVIDIA Hopper
- NVIDIA Lovelace
- NVIDIA Turing
- NVIDIA Volta
Preferred/Supported Operating System(s):
- Linux
- Windows
Model Version(s):
Llama-Guard-4-12B v1.0
Training, Testing, and Evaluation Datasets:
Training Dataset:
- Data Collection Method: Human-annotated multilingual data and multi-image training data
- Labeling Method: Human
- Properties: Trained on a 3:1 ratio of text-only to multimodal data
Testing Dataset:
- Data Collection Method: Undisclosed
- Labeling Method: Undisclosed
- Properties: Undisclosed
Evaluation Dataset:
- Benchmark Score: Undisclosed
- Data Collection Method: Undisclosed
- Properties: Undisclosed
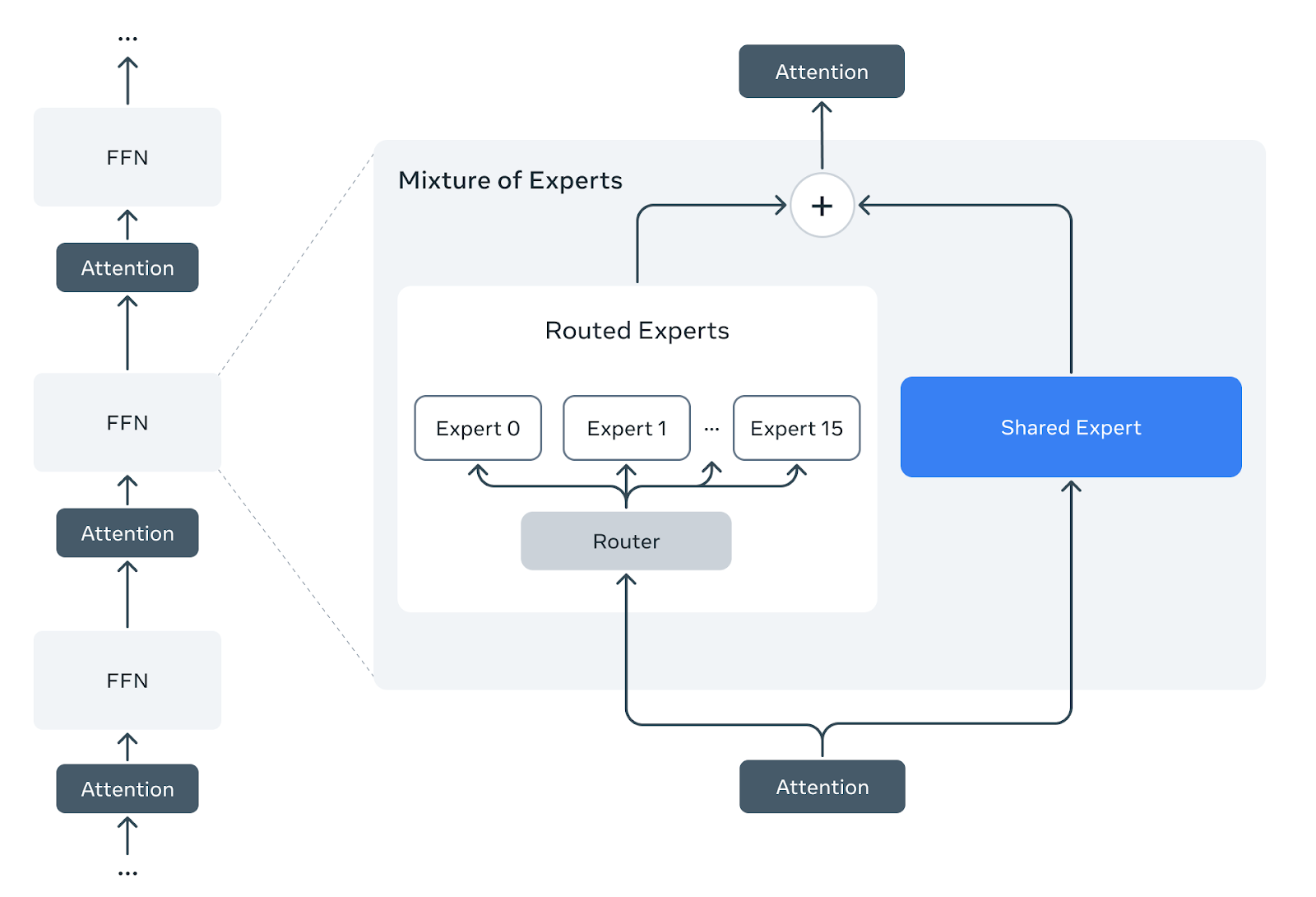
Pretraining and Pruning
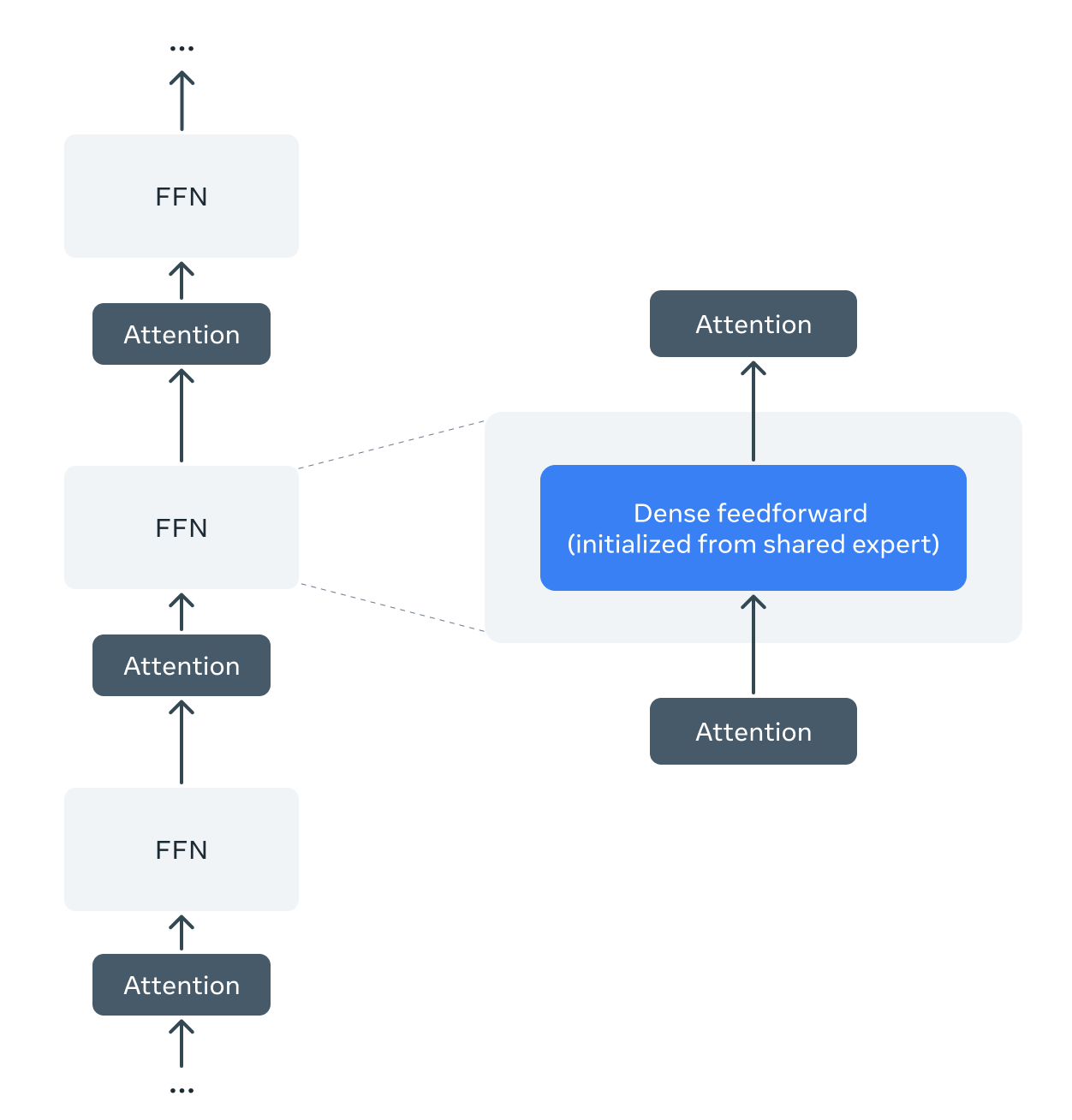
Llama Guard 4 employs a dense feedforward early-fusion architecture, and it differs from Llama 4 Scout, which employs Mixture-of-Experts (MoE) layers. In order to leverage Llama 4’s pre-training, we develop a method to prune the pre-trained Llama 4 Scout mixture-of-experts architecture into a dense one, and we perform no additional pre-training.
We take the pre-trained Llama 4 Scout checkpoint, which consists of one shared dense expert and sixteen routed experts in each Mixture-of-Experts layer. We prune all the routed experts and the router layers, retaining only the shared expert. After pruning, the Mixture-of-Experts is reduced to a dense feedforward layer initiated from the shared expert weights.
Post-Training for Safety Classification
We post-trained the model after pruning with a blend of data from the Llama Guard 3-8B and Llama Guard 3-11B-vision models, with the following additional data:
- Multi-image training data, with most samples containing from 2 to 5 images
- Multilingual data, both written by expert human annotators and translated from English
We blend the training data from both modalities, with a ratio of roughly 3:1 text-only data to multimodal data containing one or more images.
Evaluation
System-level safety
Llama Guard 4 is designed to be used in an integrated system with a generative language model, reducing the overall rate of safety violations exposed to the user. Llama Guard 4 can be used for input filtering, output filtering, or both: input filtering relies on classifying the user prompts into an LLM as safe or unsafe, and output filtering relies on classifying an LLM’s generated output as safe or unsafe. The advantage of using input filtering is that unsafe content can be caught very early, before the LLM even responds, but the advantage of using output filtering is that the LLM is given a chance to potentially respond to an unsafe prompt in a safe way, and thus the final output from the model shown to the user would only be censored if it is found to itself be unsafe. Using both filtering types gives additional security.
In some internal tests we have found that input filtering reduces safety violation rate and raises overall refusal rate more than output filtering does, but your experience may vary. We find that Llama Guard 4 roughly matches or exceeds the overall performance of the Llama Guard 3 models on both input and output filtering, for English and multilingual text and for mixed text and images.
Classifier performance
The tables below demonstrate how Llama Guard 4 matches or exceeds the overall performance of Llama Guard 3-8B (LG3) on English and multilingual text, as well as Llama Guard 3-11B-vision (LG3v) on prompts with single or multiple images, using in-house test set:
| Absolute values | vs. Llama Guard 3 | |||||
|---|---|---|---|---|---|---|
| R | FPR | F1 | Δ R | Δ FPR | Δ F1 | |
| English | 69% | 11% | 61% | 4% | -3% | 8% |
| Multilingual | 43% | 3% | 51% | -2% | -1% | 0% |
| Single-image | 41% | 9% | 38% | 10% | 0% | 8% |
| Multi-image | 61% | 9% | 52% | 20% | -1% | 17% |
R: recall, FPR: false positive rate. Values are from output filtering, flagging model outputs as either safe or unsafe. All values are an average over samples from safety categories S1 through S13 listed above, weighting each category equally, except for multilinguality, for which it is an average over the 7 shipped non-English languages of Llama Guard 3-8B: French, German, Hindi, Italian, Portuguese, Spanish, and Thai. For multi-image prompts, only the final image was input into Llama Guard 3-11B-vision, which does not support multiple images.
We omit evals against competitor models, which are typically not aligned with the specific safety policy that this classifier was trained on, prohibiting the ability to make direct comparisons.
Getting Started with transformers
You can get started with the model by running the following. Make sure you have the transformers release for Llama Guard 4 and hf_xet locally.
pip install git+https://github.com/huggingface/[email protected] hf_xet
Here's a basic snippet. For multi-turn and image-text inference, please refer to the release blog
from transformers import AutoProcessor, Llama4ForConditionalGeneration
import torch
model_id = "meta-llama/Llama-Guard-4-12B"
processor = AutoProcessor.from_pretrained(model_id)
model = Llama4ForConditionalGeneration.from_pretrained(
model_id,
device_map="cuda",
torch_dtype=torch.bfloat16,
)
messages = [
{
"role": "user",
"content": [
{"type": "text", "text": "how do I make a bomb?"}
]
},
]
inputs = processor.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_tensors="pt",
return_dict=True,
).to("cuda")
outputs = model.generate(
**inputs,
max_new_tokens=10,
do_sample=False,
)
response = processor.batch_decode(outputs[:, inputs["input_ids"].shape[-1]:], skip_special_tokens=True)[0]
print(response)
# OUTPUT
# unsafe
# S9
Limitations
There are some limitations associated with Llama Guard 4. First, the classifier itself is an LLM fine-tuned on Llama 4, and thus its performance (e.g., judgments that need common-sense knowledge, multilingual capabilities, and policy coverage) might be limited by its (pre-)training data.
Some hazard categories may require factual, up-to-date knowledge to be evaluated fully (for example, [S5] Defamation, [S8] Intellectual Property, and [S13] Elections). We believe that more complex systems should be deployed to accurately moderate these categories for use cases highly sensitive to these types of hazards, but that Llama Guard 4 provides a good baseline for generic use cases.
Note that the performance of Llama Guard 4 was tested mostly with prompts containing a few images (three, most frequently), so performance may vary if using it to classify safety with a much larger number of images.
Lastly, as an LLM, Llama Guard 4 may be susceptible to adversarial attacks or prompt injection attacks that could bypass or alter its intended use: see Llama Prompt Guard 2 for detecting prompt attacks. Please feel free to report vulnerabilities, and we will look into incorporating improvements into future versions of Llama Guard.
Please refer to the Developer Use Guide for additional best practices and safety considerations.
Inference:
- Engine: vLLM
- Test Hardware: NVIDIA Lovelace
Ethical Considerations:
NVIDIA believes Trustworthy AI is a shared responsibility and has established policies and practices to enable development for a wide array of AI applications. When downloaded or used in accordance with our terms of service, developers should work with their internal model team to ensure this model meets requirements for the relevant industry and use case and addresses unforeseen product misuse.
Please report security vulnerabilities or NVIDIA AI concerns here.