NVIDIA-Nemotron-Nano-9B-v2 Overview
NVIDIA-Nemotron-Nano-9B-v2 is a large language model (LLM) trained from scratch by NVIDIA, and designed as a unified model for both reasoning and non-reasoning tasks. It responds to user queries and tasks by first generating a reasoning trace and then concluding with a final response. The model's reasoning capabilities can be controlled via a system prompt. If the user prefers the model to provide its final answer without intermediate reasoning traces, it can be configured to do so, albeit with a slight decrease in accuracy for harder prompts that require reasoning. Conversely, allowing the model to generate reasoning traces first generally results in higher-quality final solutions to queries and tasks.
The model uses a hybrid architecture consisting primarily of Mamba-2 and MLP layers combined with just four Attention layers. For the architecture, please refer to the Nemotron-H tech report.
The supported languages include: English, German, Spanish, French, Italian, and Japanese. Improved using Qwen.
This model is ready for commercial use.
Evaluation Results
Benchmark Results (Reasoning On)
We evaluated our model in **Reasoning-On** mode across all benchmarks.
| Benchmark | NVIDIA-Nemotron-Nano-9B-v2 |
|---|---|
| AIME25 | 72.1% |
| MATH500 | 97.8% |
| GPQA | 64.0% |
| LCB | 71.1% |
| BFCL v3 | 66.9% |
| IFEVAL-Prompt | 85.4% |
| IFEVAL-Instruction | 90.3% |
All evaluations were done using NeMo-Skills.
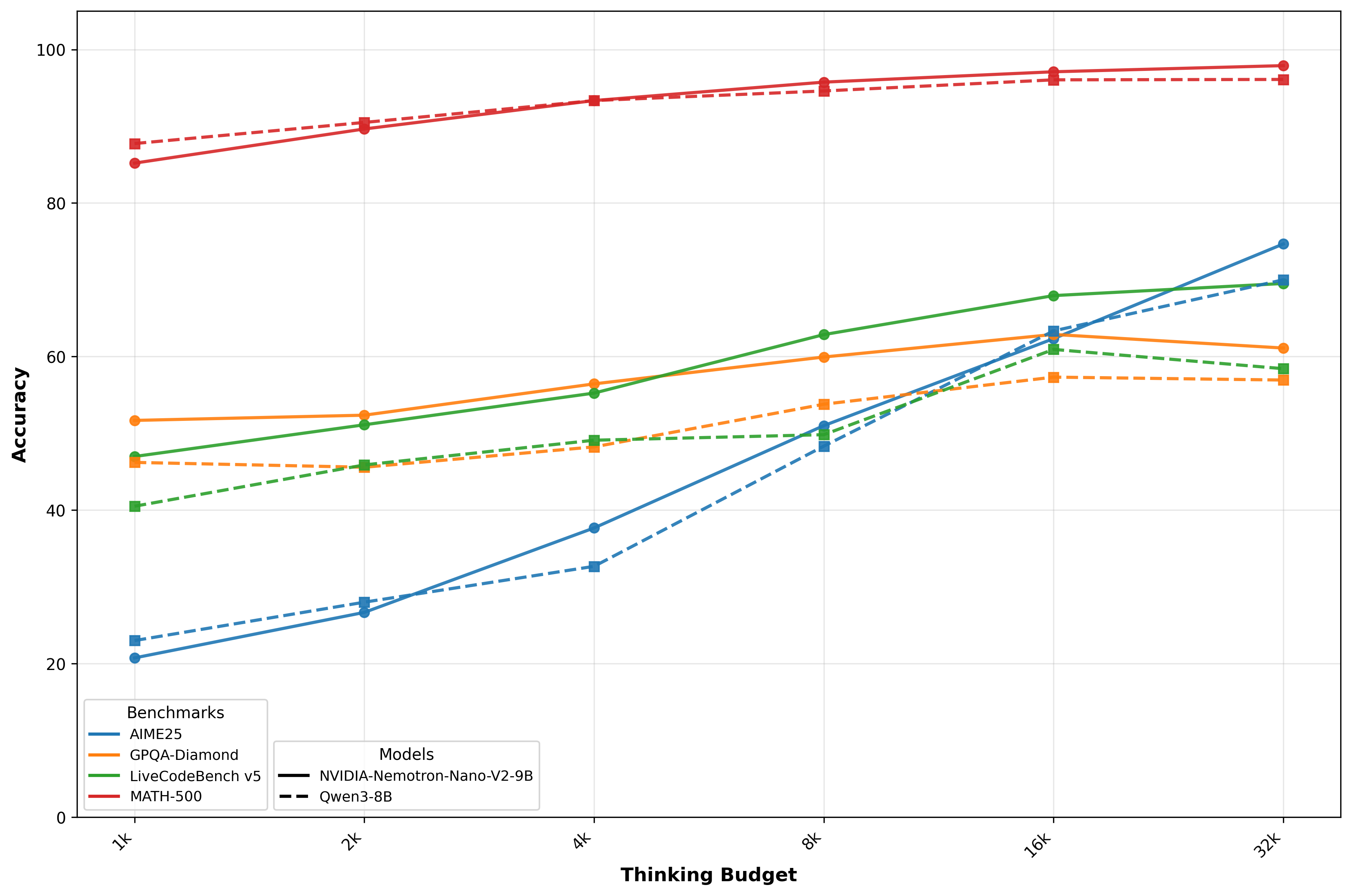
Reasoning Budget Control
This model supports runtime “thinking” budget control. During inference, the user can specify how many tokens the model is allowed to "think".
License/Terms of Use
Governing Terms: This trial service is governed by the NVIDIA API Trial Terms of Service. Use of this model is governed by the NVIDIA Open Model License Agreement.
Model Architecture
- Architecture Type: Mamba2-Transformer Hybrid
- Network Architecture: Nemotron-Hybrid
Deployment Geography: Global
Use Case
NVIDIA-Nemotron-Nano-9B-v2 is a general purpose reasoning and chat model intended to be used in English and coding languages. Other non-English languages (German, French, Italian, Spanish and Japanese) are also supported. Developers designing AI Agent systems, chatbots, RAG systems, and other AI-powered applications. Also suitable for typical instruction-following tasks.
Release Date: 08/18/2025
Huggingface 08/18/2025 via Link
API Catalog 08/18/2025 via Link
References
Computational Load
Cumulative compute : 1.53E+24 FLOPS
Estimate energy and emissions for model training: 747.6 MWh
| # of tokens | Compute [FLOPS] | Energy [MWh] | |
|---|---|---|---|
| 12B Base Pre-training | 20T | 1.45E+24 | 708.3 |
| 12B Post-training | 1T | 7.25E+22 | 35.6 |
| 9B Pruning & Distillation | 142B | 7.72E+21 | 3.7 |
| Total | 21.1T | 1.53E+24 | 747.6 |
Input
- Input Type(s): Text
- Input Format(s): String
- Input Parameters: One-Dimensional (1D): Sequences
- Other Properties Related to Input: Context length up to 128K. Supported languages include German, Spanish, French, Italian, Korean, Portuguese, Russian, Japanese, Chinese and English.
Output
- Output Type(s): Text
- Output Format: String
- Output Parameters: One-Dimensional (1D): Sequences up to 128K
Our models are designed and optimized to run on NVIDIA GPU-accelerated systems. By leveraging NVIDIA’s hardware (e.g. GPU cores) and software frameworks (e.g., CUDA libraries), the model achieves faster training and inference times compared to CPU-only solutions.
Software Integration
- Runtime Engine(s): NeMo 25.07.nemotron-nano-v2
- Supported Hardware Microarchitecture Compatibility: NVIDIA A10G, NVIDIA H100-80GB, NVIDIA A100
- Operating System(s): Linux
Use it with Transformers
The snippet below shows how to use this model with Huggingface Transformers (tested on version 4.48.3).
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
# Load tokenizer and model
tokenizer = AutoTokenizer.from_pretrained("nvidia/NVIDIA-Nemotron-Nano-9B-v2")
model = AutoModelForCausalLM.from_pretrained(
"nvidia/NVIDIA-Nemotron-Nano-9B-v2",
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map="auto"
)
Case 1: /think or no reasoning signal is provided in the system prompt, reasoning will be set to True
messages = [
{"role": "system", "content": "/think"},
{"role": "user", "content": "Write a haiku about GPUs"},
]
Case 2: /no_think is provided, reasoning will be set to False
messages = [
{"role": "system", "content": "/no_think"},
{"role": "user", "content": "Write a haiku about GPUs"},
]
Note: /think or /no_think keywords can also be provided in “user” messages for turn-level reasoning control.
The rest of the inference snippet remains the same
tokenized_chat = tokenizer.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_tensors="pt"
).to(model.device)
outputs = model.generate(
tokenized_chat,
max_new_tokens=32,
eos_token_id=tokenizer.eos_token_id
)
print(tokenizer.decode(outputs[0]))
We recommend setting temperature to 0.6, top_p to 0.95 for reasoning True and greedy search for reasoning False, and increase max_new_tokens to 1024 or higher for reasoning True.
Use it with TRT-LLM
The snippet below shows how to use this model with TRT-LLM. We tested this on the following commit and followed these instructions to build and install TRT-LLM in a docker container.
from tensorrt_llm import SamplingParams
from tensorrt_llm._torch import LLM
from tensorrt_llm._torch.pyexecutor.config import PyTorchConfig
from tensorrt_llm.llmapi import KvCacheConfig
from transformers import AutoTokenizer
pytorch_config = PyTorchConfig(
disable_overlap_scheduler=True, enable_trtllm_decoder=True
)
kv_cache_config = KvCacheConfig(
enable_block_reuse=False,
)
model_id = "nvidia/NVIDIA-Nemotron-Nano-9B-v2"
tokenizer = AutoTokenizer.from_pretrained(model_id)
llm = LLM(
model=model_id,
max_seq_len=32678,
max_batch_size=4,
pytorch_backend_config=pytorch_config,
kv_cache_config=kv_cache_config,
tensor_parallel_size=8,
)
messages = [
{"role": "system", "content": "/think"},
{"role": "user", "content": "Write a haiku about GPUs"},
]
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
sampling_params = SamplingParams(
max_tokens=512,
temperature=0.6,
top_p=0.95,
add_special_tokens=False,
)
outputs = llm.generate([prompt], sampling_params)
print(outputs[0].outputs[0].text)
Use it with vLLM
The snippet below shows how to use this model with vLLM. Use the following commit and follow these instructions to build and install vLLM in a docker container.
# use full commit hash from the main branch
export VLLM_COMMIT=75531a6c134282f940c86461b3c40996b4136793
uv pip install vllm --extra-index-url https://wheels.vllm.ai/${VLLM_COMMIT}
Now you can run run the server with:
vllm serve nvidia/NVIDIA-Nemotron-Nano-9B-v2 \
--trust-remote-code \
--mamba_ssm_cache_dtype float32
Note: Remember to add `--mamba_ssm_cache_dtype float32` for accurate quality. Without this option, the model’s accuracy may degrade.
Using Budget Control with a vLLM Server
The thinking budget allows developers to keep accuracy high and meet response‑time targets - which is especially crucial for customer support, autonomous agent steps, and edge devices where every millisecond counts.
With budget control, you can set a limit for internal reasoning:
max_thinking_tokens: This is a threshold that will attempt to end the reasoning trace at the next newline encountered in the reasoning trace. If no newline is encountered within 500 tokens, it will abruptly end the reasoning trace at `max_thinking_tokens + 500`.
Start a vLLM server:
vllm serve nvidia/NVIDIA-Nemotron-Nano-9B-v2 \
--trust-remote-code \
--mamba_ssm_cache_dtype float32
Client for supporting budget control:
from typing import Any, Dict, List
import openai
from transformers import AutoTokenizer
class ThinkingBudgetClient:
def __init__(self, base_url: str, api_key: str, tokenizer_name_or_path: str):
self.base_url = base_url
self.api_key = api_key
self.tokenizer = AutoTokenizer.from_pretrained(tokenizer_name_or_path)
self.client = openai.OpenAI(base_url=self.base_url, api_key=self.api_key)
def chat_completion(
self,
model: str,
messages: List[Dict[str, Any]],
max_thinking_budget: int = 512,
max_tokens: int = 1024,
**kwargs,
) -> Dict[str, Any]:
assert (
max_tokens > max_thinking_budget
), f"thinking budget must be smaller than maximum new tokens. Given {max_tokens=} and {max_thinking_budget=}"
# 1. first call chat completion to get reasoning content
response = self.client.chat.completions.create(
model=model, messages=messages, max_tokens=max_thinking_budget, **kwargs
)
content = response.choices[0].message.content
reasoning_content = content
if not "</think>" in reasoning_content:
# reasoning content is too long, closed with a period (.)
reasoning_content = f"{reasoning_content}.\n</think>\n\n"
reasoning_tokens_len = len(
self.tokenizer.encode(reasoning_content, add_special_tokens=False)
)
remaining_tokens = max_tokens - reasoning_tokens_len
assert (
remaining_tokens > 0
), f"remaining tokens must be positive. Given {remaining_tokens=}. Increase the max_tokens or lower the max_thinking_budget."
# 2. append reasoning content to messages and call completion
messages.append({"role": "assistant", "content": reasoning_content})
prompt = self.tokenizer.apply_chat_template(
messages,
tokenize=False,
continue_final_message=True,
)
response = self.client.completions.create(
model=model, prompt=prompt, max_tokens=max_tokens, **kwargs
)
response_data = {
"reasoning_content": reasoning_content.strip().strip("</think>").strip(),
"content": response.choices[0].text,
"finish_reason": response.choices[0].finish_reason,
}
return response_data
Calling the server with a budget (Restricted to 32 tokens here as an example)
tokenizer_name_or_path = "nvidia/NVIDIA-Nemotron-Nano-9B-v2"
client = ThinkingBudgetClient(
base_url="http://localhost:8000/v1", # Nano 9B v2 deployed in thinking mode
api_key="EMPTY",
tokenizer_name_or_path=tokenizer_name_or_path,
)
result = client.chat_completion(
model="nvidia/NVIDIA-Nemotron-Nano-9B-v2",
messages=[
{"role": "system", "content": "You are a helpful assistant. /think"},
{"role": "user", "content": "What is 2+2?"},
],
max_thinking_budget=32,
max_tokens=512,
temperature=0.6,
top_p=0.95,
)
print(result)
You should see output similar to the following:
{'reasoning_content': "Okay, the user asked, What is 2+2? Let me think. Well, 2 plus 2 equals 4. That's a basic.", 'content': '2 + 2 equals **4**.\n', 'finish_reason': 'stop'}
Using Tool-Calling with a vLLM Server
Start a vLLM server with native tool-calling:
git clone https://huggingface.co/nvidia/nvidia/NVIDIA-Nemotron-Nano-9B-v2
vllm serve nvidia/NVIDIA-Nemotron-Nano-9B-v2 \
--trust-remote-code \
--mamba_ssm_cache_dtype float32
--enable-auto-tool-choice \
--tool-parser-plugin "NVIDIA-Nemotron-Nano-9B-v2/nemotron_toolcall_parser_no_streaming.py" \
--tool-call-parser "nemotron_json"
After launching a vLLM server, you can call the server with tool-call support using a Python script like below:
from openai import OpenAI
client = OpenAI(
base_url="http://0.0.0.0:5000/v1",
api_key="dummy",
)
completion = client.chat.completions.create(
model="nvidia/NVIDIA-Nemotron-Nano-9B-v2",
messages=[
{"role": "system", "content": ""},
{"role": "user", "content": "My bill is $100. What will be the amount for 18% tip?"}
],
tools=[
{
"type": "function",
"function": {
"name": "calculate_tip",
"parameters": {
"type": "object",
"properties": {
"bill_total": {
"type": "integer",
"description": "The total amount of the bill"
},
"tip_percentage": {
"type": "integer",
"description": "The percentage of tip to be applied"
}
},
"required": ["bill_total", "tip_percentage"]
}
}
},
{
"type": "function",
"function": {
"name": "convert_currency",
"parameters": {
"type": "object",
"properties": {
"amount": {
"type": "integer",
"description": "The amount to be converted"
},
"from_currency": {
"type": "string",
"description": "The currency code to convert from"
},
"to_currency": {
"type": "string",
"description": "The currency code to convert to"
}
},
"required": ["from_currency", "amount", "to_currency"]
}
}
}
],
temperature=0.6,
top_p=0.95,
max_tokens=32768,
stream=False
)
print(completion.choices[0].message.content)
print(completion.choices[0].message.tool_calls)
You should see output similar to the following:
<think>
Okay, let's see. The user has a bill of $100 and wants to know the amount for an 18% tip. Hmm, I need to calculate the tip based on the bill total and the percentage. The tools provided include calculate_tip, which takes bill_total and tip_percentage as parameters. So the bill_total here is 100, and the tip_percentage is 18. I should call the calculate_tip function with these values. Wait, do I need to check if the parameters are integers? The bill is $100, which is an integer, and 18% is also an integer. So that fits the function's requirements. I don't need to convert any currency here because the user is asking about a tip in the same currency. So the correct tool to use is calculate_tip with those parameters.
</think>
[ChatCompletionMessageToolCall(id='chatcmpl-tool-e341c6954d2c48c2a0e9071c7bdefd8b', function=Function(arguments='{"bill_total": 100, "tip_percentage": 18}', name='calculate_tip'), type='function')]
Model Version
- v1.0
Prompt Format
We follow the jinja chat template provided below. This template conditionally adds <think>\n to the start of the Assistant response if /think is found in the system prompt or if no reasoning signal is added, and adds <think></think> to the start of the Assistant response if /no_think is found in the system prompt. Thus enforcing reasoning on/off behavior.
{%- set ns = namespace(enable_thinking = true) %}
{%- for message in messages -%}
{%- set content = message['content'] -%}
{%- if message['role'] == 'user' or message['role'] == 'system' -%}
{%- if '/think' in content -%}
{%- set ns.enable_thinking = true -%}
{%- elif '/no_think' in content -%}
{%- set ns.enable_thinking = false -%}
{%- endif -%}
{%- endif -%}
{%- endfor -%}
{%- if messages[0]['role'] != 'system' -%}
{%- set ns.non_tool_system_content = '' -%}
{{- '<SPECIAL_10>System\n' -}}
{%- else -%}
{%- set ns.non_tool_system_content = messages[0]['content']
.replace('/think', '')
.replace('/no_think', '')
.strip()
-%}
{{- '<SPECIAL_10>System\n' + ns.non_tool_system_content }}
{%- endif -%}
{%- if tools -%}
{%- if ns.non_tool_system_content is defined and ns.non_tool_system_content != '' -%}
{{- '\n\n' -}}
{%- endif -%}
{{- 'You can use the following tools to assist the user if required:' -}}
{{- '\n<AVAILABLE_TOOLS>[' -}}
{%- for tool in tools -%}
{{- (tool.function if tool.function is defined else tool) | tojson -}}
{{- ', ' if not loop.last else '' -}}
{%- endfor -%}
{{- ']</AVAILABLE_TOOLS>\n\n' -}}
{{- 'If you decide to call any tool(s), use the following format:\n' -}}
{{- '<TOOLCALL>[{{"name": "tool_name1", "arguments": "tool_args1"}}, ' -}}
{{- '{{"name": "tool_name2", "arguments": "tool_args2"}}]</TOOLCALL>\n\n' -}}
{{- 'The user will execute tool-calls and return responses from tool(s) in this format:\n' -}}
{{- '<TOOL_RESPONSE>[{{"tool_response1"}}, {{"tool_response2"}}]</TOOL_RESPONSE>\n\n' -}}
{{- 'Based on the tool responses, you can call additional tools if needed, correct tool calls if any errors are found, or just respond to the user.' -}}
{%- endif -%}
{{- '\n' -}}
{%- set messages = messages[1:] if messages[0]['role'] == 'system' else messages -%}
{%- if messages[-1]['role'] == 'assistant' -%}
{%- set ns.last_turn_assistant_content = messages[-1]['content'].strip() -%}
{%- set messages = messages[:-1] -%}
{%- endif -%}
{%- for message in messages -%}
{%- set content = message['content'] -%}
{%- if message['role'] == 'user' -%}
{{- '<SPECIAL_11>User\n' + content.replace('/think', '').replace('/no_think', '').strip() + '\n' }}
{%- elif message['role'] == 'tool' -%}
{%- if loop.first or (messages[loop.index0 - 1].role != 'tool') -%}
{{- '<SPECIAL_11>User\n' + '<TOOL_RESPONSE>[' }}
{%- endif -%}
{{- message['content'] -}}
{{- ', ' if not loop.last and (messages[loop.index0 + 1].role == 'tool') else '' -}}
{%- if loop.last or (messages[loop.index0 + 1].role != 'tool') -%}
{{- ']</TOOL_RESPONSE>\n' -}}
{%- endif -%}
{%- elif message['role'] == 'assistant' -%}
{%- if '</think>' in content -%}
{%- set content = content.split('</think>')[1].strip() %}
{%- endif -%}
{{- '<SPECIAL_11>Assistant\n' + content.strip() }}
{%- if message.tool_calls -%}
{%- if content.strip() != '' -%}
{{- '\n\n' -}}
{%- endif -%}
{{- '<TOOLCALL>[' -}}
{%- for call in message.tool_calls -%}
{%- set fn = call.function if call.function is defined else call -%}
{{- '{"name": "' + fn.name + '", "arguments": ' -}}
{%- if fn.arguments is string -%}
{{- fn.arguments -}}
{%- else -%}
{{- fn.arguments | tojson -}}
{%- endif -%}
{{- '}' + (', ' if not loop.last else '') -}}
{%- endfor -%}
{{- ']</TOOLCALL>' -}}
{%- endif -%}
{{- '\n<SPECIAL_12>\n' -}}
{%- endif -%}
{%- endfor -%}
{%- if add_generation_prompt -%}
{{- '<SPECIAL_11>Assistant\n' -}}
{%- if ns.enable_thinking is defined and ns.enable_thinking is false -%}
{{- '<think></think>' -}}
{%- else -%}
{{- '<think>\n' -}}
{%- endif -%}
{%- if ns.last_turn_assistant_content is defined and ns.last_turn_assistant_content != '' -%}
{{- ns.last_turn_assistant_content -}}
{%- endif -%}
{%- else -%}
{%- if ns.last_turn_assistant_content is defined and ns.last_turn_assistant_content != '' -%}
{{- '<SPECIAL_11>Assistant\n' -}}
{%- if ns.enable_thinking is defined and ns.enable_thinking is false -%}
{{- '<think></think>' -}}
{%- else -%}
{{- '<think>\n' -}}
{%- endif -%}
{{- ns.last_turn_assistant_content -}}
{%- if continue_final_message is defined -%}
{%- if continue_final_message is false -%}
{{- '\n<SPECIAL_12>\n' -}}
{%- endif -%}
{%- else -%}
{{- '\n<SPECIAL_12>\n' -}}
{%- endif -%}
{%- endif -%}
{%- endif -%}
Training, Testing, and Evaluation Datasets
Training datasets
- Data Modality: Text
- Text Training Data Size: More than 10 Trillion Tokens
- Train/Test/Valid Split: We used 100% of the corpus for pre-training and relied on external benchmarks for testing.
- Data Collection Method by dataset: Hybrid: Automated, Human, Synthetic
- Labeling Method by dataset: Hybrid: Automated, Human, Synthetic
Properties: The post-training corpus for NVIDIA-Nemotron-Nano-9B-v2 consists of English and multilingual text (German, Spanish, French, Italian, Korean, Portuguese, Russian, Japanese, Chinese and English). Our sources cover a variety of document types such as: webpages, dialogue, articles, and other written materials. The corpus spans domains including code, legal, math, science, finance, and more. We also include a small portion of question-answering, and alignment style data to improve model accuracies. For several of the domains listed above we used synthetic data, specifically reasoning traces, from DeepSeek R1/R1-0528, Qwen3-235B-A22B, Nemotron 4 340B, Qwen2.5-32B-Instruct-AWQ, Qwen2.5-14B-Instruct, Qwen 2.5 72B.
The pre-training corpus for NVIDIA-Nemotron-Nano-9B-v2 consists of high-quality curated and synthetically-generated data. It is trained in the English language, as well as 15 multilingual languages and 43 programming languages. Our sources cover a variety of document types such as: webpages, dialogue, articles, and other written materials. The corpus spans domains including legal, math, science, finance, and more. We also include a small portion of question-answering, and alignment style data to improve model accuracy. The model was pre-trained for approximately twenty trillion tokens.
More details on the datasets and synthetic data generation methods can be found in the technical report NVIDIA Nemotron Nano 2: An Accurate and Efficient Hybrid Mamba-Transformer Reasoning Model .
Public Datasets
Private Non-publicly Accessible Datasets of Third Parties
| Dataset |
|---|
| Global Regulation |
| Workbench |
Online Dataset Sources
The English Common Crawl data was downloaded from the Common Crawl Foundation (see their FAQ for details on their crawling) and includes the snapshots CC-MAIN-2013-20 through CC-MAIN-2025-13. The data was subsequently deduplicated and filtered in various ways described in the Nemotron-CC paper.
Additionally, we extracted data for fifteen languages from the following three Common Crawl snapshots: CC-MAIN-2024-51, CC-MAIN-2025-08, CC-MAIN-2025-18. The fifteen languages included were Arabic, Chinese, Danish, Dutch, French, German, Italian, Japanese, Korean, Polish, Portuguese, Russian, Spanish, Swedish, and Thai. As we did not have reliable multilingual model-based quality classifiers available, we applied just heuristic filtering instead—similar to what we did for lower quality English data in the Nemotron-CC pipeline, but selectively removing some filters for some languages that did not work well. Deduplication was done in the same way as for Nemotron-CC.
The GitHub Crawl was collected using the GitHub REST API and the Amazon S3 API. Each crawl was operated in accordance with the rate limits set by its respective source, either GitHub or S3. We collect raw source code and subsequently remove any having a license which does not exist in our permissive-license set (for additional details, refer to the technical report).
| Dataset | Modality | Dataset Size (Tokens) | Collection Period |
|---|---|---|---|
| English Common Crawl | Text | 3.360T | 4/8/2025 |
| Multilingual Common Crawl | Text | 812.7B | 5/1/2025 |
| GitHub Crawl | Text | 747.4B | 4/29/2025 |
NVIDIA-Sourced Synthetic Datasets
| Dataset | Modality | Dataset Size (Tokens) | Seed Dataset | Model(s) used for generation |
|---|---|---|---|---|
| Synthetic Art of Problem Solving from DeepSeek-R1 | Text | 25.5B | Art of Problem Solving; American Mathematics Competitions 8; American Mathematics Competitions 10; | DeepSeek-R1 |
| Synthetic Moral Stories and Social Chemistry from Mixtral-8x22B-v0.1 | Text | 327M | social-chemestry-101; Moral Stories | Mixtral-8x22B-v0.1 |
| Synthetic Social Sciences seeded with OpenStax from DeepSeek-V3, Mixtral-8x22B-v0.1, and Qwen2.5-72B | Text | 83.6M | OpenStax - CC BY-SA subset | DeepSeek-V3; Mixtral-8x22B-v0.1; Qwen2.5-72B |
| Synthetic Health Sciences seeded with OpenStax from DeepSeek-V3, Mixtral-8x22B-v0.1, and Qwen2.5-72B | Text | 9.7M | OpenStax - CC BY-SA subset | DeepSeek-V3; Mixtral-8x22B-v0.1; Qwen2.5-72B |
| Synthetic STEM seeded with OpenStax, Open Textbook Library, and GSM8K from DeepSeek-R1, DeepSeek-V3, DeepSeek-V3-0324, and Qwen2.5-72B | Text | 175M | OpenStax - CC BY-SA subset; GSM8K; Open Textbook Library - CC BY-SA & GNU subset | DeepSeek-R1, DeepSeek-V3; DeepSeek-V3-0324; Qwen2.5-72B |
| Nemotron-PrismMath | Text | 4.6B | Big-Math-RL-Verified; OpenR1-Math-220k | Qwen2.5-0.5B-instruct, Qwen2.5-72B-Instruct; DeepSeek-R1-Distill-Qwen-32B |
| Synthetic Question Answering Data from Papers and Permissible Books from Qwen2.5-72B-Instruct | Text | 350M | arXiv; National Institutes of Health ExPorter; BioRxiv; PMC Article; USPTO Backgrounds; peS2o; Global Regulation; CORE; PG-19; DOAB CC BY & CC BY-SA subset; NDLTD | Qwen2.5-72B-Instruct |
| Synthetic FineMath-4+ Reprocessed from DeepSeek-V3 | Text | 9.2B | Common Crawl | DeepSeek-V3 |
| Synthetic FineMath-3+ Reprocessed from phi-4 | Text | 27.6B | Common Crawl | phi-4 |
| Synthetic Union-3+ Reprocessed from phi-4 | Text | 93.1B | Common Crawl | phi-4 |
| Refreshed Nemotron-MIND from phi-4 | Text | 73B | Common Crawl | phi-4 |
| Synthetic Union-4+ Reprocessed from phi-4 | Text | 14.12B | Common Crawl | phi-4 |
| Synthetic Union-3+ minus 4+ Reprocessed from phi-4 | Text | 78.95B | Common Crawl | phi-4 |
| Synthetic Union-3 Refreshed from phi-4 | Text | 80.94B | Common Crawl | phi-4 |
| Synthetic Union-4+ Refreshed from phi-4 | Text | 52.32B | Common Crawl | phi-4 |
| Synthetic AGIEval seeded with AQUA-RAT, LogiQA, and AR-LSAT from DeepSeek-V3 and DeepSeek-V3-0324 | Text | 4.0B | AQUA-RAT; LogiQA; AR-LSAT | DeepSeek-V3; DeepSeek-V3-0324 |
| Synthetic AGIEval seeded with AQUA-RAT, LogiQA, and AR-LSAT from Qwen3-30B-A3B | Text | 4.2B | AQUA-RAT; LogiQA; AR-LSAT | Qwen3-30B-A3B |
| Synthetic Art of Problem Solving from Qwen2.5-32B-Instruct, Qwen2.5-Math-72B, Qwen2.5-Math-7B, and Qwen2.5-72B-Instruct | Text | 83.1B | Art of Problem Solving; American Mathematics Competitions 8; American Mathematics Competitions 10; GSM8K; PRM800K | Qwen2.5-32B-Instruct; Qwen2.5-Math-72B; Qwen2.5-Math-7B; Qwen2.5-72B-Instruct |
| Synthetic MMLU Auxiliary Train from DeepSeek-R1 | Text | 0.5B | MMLU Auxiliary Train | DeepSeek-R1 |
| Synthetic Long Context Continued Post-Training Data from Papers and Permissible Books from Qwen2.5-72B-Instruct | Text | 5.4B | arXiv; National Institutes of Health ExPorter; BioRxiv; PMC Article; USPTO Backgrounds; peS2o; Global Regulation; CORE; PG-19; DOAB CC BY & CC BY-SA subset; NDLTD | Qwen2.5-72B-Instruct |
| Synthetic Common Crawl from Qwen3-30B-A3B and Mistral-Nemo-12B-Instruct | Text | 1.949T | Common Crawl | Qwen3-30B-A3B; Mistral-NeMo-12B-Instruct |
| Synthetic Multilingual Data from Common Crawl from Qwen3-30B-A3B | Text | 997.3B | Common Crawl | Qwen3-30B-A3B |
| Synthetic Multilingual Data from Wikimedia from Qwen3-30B-A3B | Text | 55.1B | Wikimedia | Qwen3-30B-A3B |
| Synthetic OpenMathReasoning from DeepSeek-R1-0528 | Text | 1.5M | OpenMathReasoning | DeepSeek-R1-0528 |
| Synthetic OpenCodeReasoning from DeepSeek-R1-0528 | Text | 1.1M | OpenCodeReasoning | DeepSeek-R1-0528 |
| Synthetic Science Data from DeepSeek-R1-0528 | Text | 1.5M | - | DeepSeek-R1-0528 |
| Synthetic Humanity's Last Exam from DeepSeek-R1-0528 | Text | 460K | Humanity's Last Exam | DeepSeek-R1-0528 |
| Synthetic ToolBench from Qwen3-235B-A22B | Text | 400K | ToolBench | Qwen3-235B-A22B |
| Synthetic Nemotron Content Safety Dataset V2, eval-safety, Gretel Synthetic Safety Alignment, and RedTeam_2K from DeepSeek-R1-0528 | Text | 52K | Nemotron Content Safety Dataset V2; eval-safety; Gretel Synthetic Safety Alignment; RedTeam_2K | DeepSeek-R1-0528 |
| Synthetic HelpSteer from Qwen3-235B-A22B | Text | 120K | HelpSteer3; HelpSteer2 | Qwen3-235B-A22B |
| Synthetic Alignment data from Mixtral-8x22B-Instruct-v0.1, Mixtral-8x7B-Instruct-v0.1, and Nemotron-4 Family | Text | 400K | HelpSteer2; C4; LMSYS-Chat-1M; ShareGPT52K; tigerbot-kaggle-leetcodesolutions-en-2k; GSM8K; PRM800K; lm_identity (NVIDIA internal); FinQA; WikiTableQuestions; Riddles; ChatQA nvolve-multiturn (NVIDIA internal); glaive-function-calling-v2; SciBench; OpenBookQA; Advanced Reasoning Benchmark; Public Software Heritage S3; Khan Academy Math Keywords | Nemotron-4-15B-Base (NVIDIA internal); Nemotron-4-15B-Instruct (NVIDIA internal); Nemotron-4-340B-Base; Nemotron-4-340B-Instruct; Nemotron-4-340B-Reward; Mixtral-8x7B-Instruct-v0.1; Mixtral-8x22B-Instruct-v0.1 |
| Synthetic LMSYS-Chat-1M from Qwen3-235B-A22B | Text | 1M | LMSYS-Chat-1M | Qwen3-235B-A22B |
| Synthetic Multilingual Reasoning data from DeepSeek-R1-0528, Qwen2.5-32B-Instruct-AWQ, and Qwen2.5-14B-Instruct | Text | 25M | OpenMathReasoning; OpenCodeReasoning | DeepSeek-R1-0528; Qwen2.5-32B-Instruct-AWQ (translation); Qwen2.5-14B-Instruct (translation); |
| Synthetic Multilingual Reasoning data from Qwen3-235B-A22B and Gemma 3 Post-Trained models | Text | 5M | WildChat | Qwen3-235B-A22B; Gemma 3 PT 12B; Gemma 3 PT 27B |
Evaluation Dataset:
- Data Collection Method by dataset: Hybrid: Human, Synthetic
- Labeling Method by dataset: Hybrid: Automated, Human, Synthetic
Inference
-
Engines: vLLM
-
Test Hardware NVIDIA: 1*H100.
Ethical Considerations
NVIDIA believes Trustworthy AI is a shared responsibility and we have established policies and practices to enable development for a wide array of AI applications. When downloaded or used in accordance with our Trustworthy AI terms of service, developers should work with their internal model team to ensure this model meets requirements for the relevant industry and use case and addresses unforeseen product misuse.
For more detailed information on ethical considerations for this model, please see the Model Card++ Bias, Explainability, Safety & Security, and Privacy Subcards.
Please report security vulnerabilities or NVIDIA AI Concerns here.